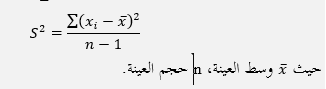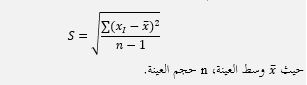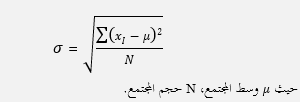عزيزي القارئ في هذا المقال سنتناول استخدام الاكسل لحساب الخطأ المعياري للتقدير
تذكير:
يقيس الخطأ المعياري للتقدير Standard Error مدى التشتت حول مستقيم الانحدار الذي يمثل العلاقة بين متغيرين، ويحسب في الإحصاء باستخدام العلاقة:
حيث القيم التقديرية لـ Y والتي نحصل عليها من معادلة الانحدار، القيم الفعلية لـ Y، n حجم العينة..
يتضمن برنامج Microsoft Excel الدالة STEYXلحساب الخطأ المعياري للتقدير
الدالة STEYX
تُستخدم الدالة STEYX لحساب خطأ المعياري للتقدير والشكل العام لهذه الدالة هو:
= STEYX(Known_y’s; Known_x’s)
حيث:
Known_x’s: تمثل نطاق الخلايا المرجعية لقيم المتغير x.
Known_y’s: تمثل نطاق الخلايا المرجعية لقيم المتغير Y.
ملاحظات
1-يجب أن تكون بيانات الوسطاء أرقاماً أو مراجع خلايا تحتوي على أرقام.
2- إذا احتوت وسيطة نطاق خلايا أو مرجع على نص أو قيم منطقية أو خلايا فارغة، يتم تجاهل تلك القيم، وبالرغم من ذلك، يتم تضمين الخلايا التي تحتوي على قيمة الصفر (0).
3-إذا كان عدد بيانات المتغيرين (عدد خلايا الوسطاء Known_y’s و Known_x’s) غير متساوي عندئذ ترجع الدالة قيمة الخطأ غير قابل للتطبيق #N/A
4- إذا كانت أي من Known_y’s و Known_x’s فارغة أو يحتوي كل منهما على نقطة بيانات واحدة فقط، تُرجع الدالة STEYXقيمة الخطأ #DIV/0!..
تطبيق عملي (1)
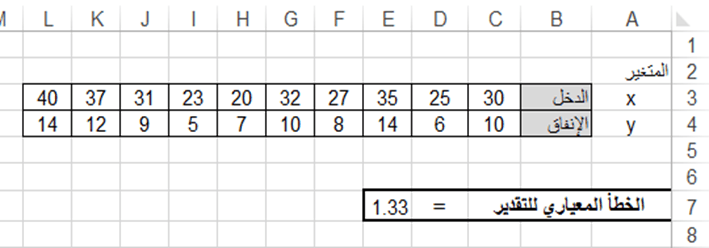
احسب الخطأ المعياري للتقدير لبيانات الجدول التالي الذي يمثل الدخل والإنفاق على المعيشة لمجموعة من الأسر بآلاف الليرات السورية شهرياً، حيث Y يمثل الإنفاق على المعيشة وX يمثل دخل الأسرة.
التنفيذ:
من أجل حساب الخطأ المعياري للتقدير باستخدام الدالة STEYX ندخل في الخلية E7 الدالة:
= STEYX(C4:L4; C3:L3)
في النهاية أعزائي القراء أتمنى أن تكون هذه التدوينة مفيدة وتساعدكم لمعرفة المزيد عن الاكسل، وإلى لقاءات قادمة ومتجددة على مدونتكم مدونة النائب للعلوم والتكنلوجيا. وأريد أن أطلب منكم ألا تترددوا أبداً في طرح أي سؤال علينا في التعليقات أو من خلال صفحتنا الرسمية على الفيس بوك حيث نتواجد هناك باستمرار. وإذا كان لديكم استفسارات أخرى يمكنكم دائماً مرسلتنا عبر هذا الرابط.
عزيزي القارئ في هذا المقال سنتناول استخدام الاكسل لحساب معامل الارتباط ومعامل التحديد
تذكير:
يستخدم معامل الارتباط Correlation Coefficient لقياس كثافة العلاقة الارتباطية بين متغيرين X وY، وذلك عندما لا يكون لدينا معلومات عن أي من المتغيرين يعتبر مستقلاً أو تابعاً.
تذكير:
معاملات الارتباط هي مؤشرات لمعرفة قوة العلاقة الخطية بين متغيرين مختلفين، ويشير معامل الارتباط الخطي الأكبر من الصفر إلى وجود علاقة موجبة، والأقل من الصفر إلى وجود علاقة سالبة، وتشير القيمة صفر إلى عدم وجود علاقة بين المتغيرين. حيث: عندما r=0.4 يشير إلى علاقة إيجابية قوية
تذكير:
يُعرف معامل التحديد coefficient of determination بأنه مربع معامل الارتباط، ويُرمز إليه بـ “آر التربيعية” (R2)، ويُستخدم لتفسير التباين في متغير واحد من خلال تغيير في متغير ثانٍ، ويمكن تمثيله على أساس قيمة بين 0 و1، وكلما كانت القيمة أقرب على واحد كان التناسب أفضل.
يتضمن برنامج Microsoft Excel دالتين إحصائيتين لحساب معامل الارتباط PEARSON و CORREL. ودالة RSQ لحساب معامل التحديد
الدالةمعامل الارتباط PEARSON
تُستخدم الدالة PEARSON لحساب معامل ارتباط بيرسون والشكل العام لهذه الدالة هو:
= PEARSON(Array1; Array2)
حيث:
Array1: تمثل نطاق الخلايا المرجعية لقيم أحد المتغيرين x أو y.
Array2: تمثل نطاق الخلايا المرجعية لقيم المتغير الآخر.
دالة معامل الارتباط CORREL
تُستخدم الدالة CORREL أيضاً لحساب معامل ارتباط والشكل العام لهذه الدالة هو:
= CORREL(Array1; Array2)
حيث:
Array1: تمثل نطاق الخلايا المرجعية لقيم أحد المتغيرين x أو y.
Array2: تمثل نطاق الخلايا المرجعية لقيم المتغير الآخر.
دالة معامل التحديد RSQ
تُستخدم الدالة RSQ معامل التحديد والشكل العام لهذه الدالة هو:
= RSQ(Known_y’s; Known_x’s)
حيث:
Known_x’s: تمثل نطاق الخلايا المرجعية لقيم المتغير x.
Known_y’s: تمثل نطاق الخلايا المرجعية لقيم المتغير Y.
ملاحظات حول الدوال RSQ – PEARSONE -CORREL
1-يجب أن تكون بيانات الوسطاء أرقاماً أو مراجع خلايا تحتوي على أرقام.
2-إذا احتوت بعض خلايا نطاق الخلايا المطبق عليها الدالة على نص أو قيمة منطقية أو أنها فارغة فيتم تجاهلها.
3-إذا كان عدد بيانات المتغيرين (عدد خلايا الوسطاء Known_y’s و Known_x’s) غير متساوي عندئذ ترجع الدالة قيمة الخطأ غير قابل للتطبيق #N/A
4- ترجع الدالة قيمة الخطأ #DIV/0! إذا كان الانحراف المعياري لقيم المتغيرين المستقل والتابع (الانحراف المعياري للوسيطة Known_x’s أو للوسيطة Known_y’s) يساوي الصفر.
تطبيق عملي (1)
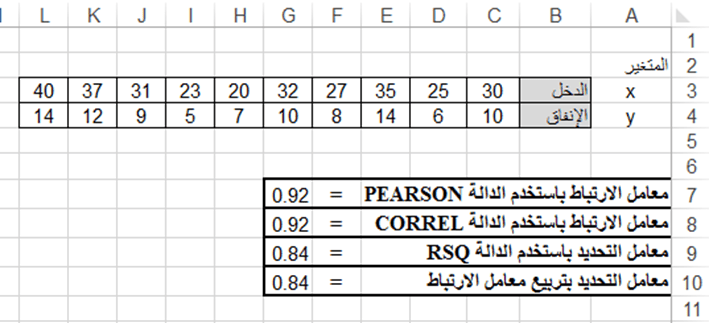
احسب معامل الارتباط ومعامل التحديد لبيانات الجدول التالي الذي يمثل الدخل والإنفاق على المعيشة لمجموعة من الأسر بآلاف الليرات السورية شهرياً، حيث Y يمثل الإنفاق على المعيشة وX يمثل دخل الأسرة.
التنفيذ:
من أجل حساب معامل الارتباط باستخدام الدالة PEARSONE ندخل في الخلية G7 الدالة:
= PEARSONE (C3:L3; C4:L4)
أو الدالة:
= PEARSONE (C4:L4; C3:L3)
من أجل حساب معامل الارتباط باستخدام الدالة CORREL ندخل في الخلية G8 الدالة:
= CORREL (C3:L3; C4:L4)
أو الدالة:
= CORREL (C4:L4; C3:L3)
من أجل حساب معامل التحديد باستخدام الدالة RSQ ندخل في الخلية G9 الدالة:
= RSQ (C3:L3; C4:L4)
أو الدالة:
= RSQ (C4:L4; C3:L3)
من أجل حساب معامل التحديد بتربيع معامل الارتباط ندخل في الخلية G10 الصيغة:
= G7^2
في النهاية أعزائي القراء أتمنى أن تكون هذه التدوينة مفيدة وتساعدكم لمعرفة المزيد عن الاكسل، وإلى لقاءات قادمة ومتجددة على مدونتكم مدونة النائب للعلوم والتكنلوجيا. وأريد أن أطلب منكم ألا تترددوا أبداً في طرح أي سؤال علينا في التعليقات أو من خلال صفحتنا الرسمية على الفيس بوك حيث نتواجد هناك باستمرار. وإذا كان لديكم استفسارات أخرى يمكنكم دائماً مرسلتنا عبر هذا الرابط.
عزيزي القارئ تتمثل إحدى القيم المهمة لمعادلة الانحدار المقدرة في قدرتها على التنبؤ بقيم المتغير التابع Y بتأثيرات التغيير في قيمة المتغير المستقل X
في هذا المقال سنتناول استخدام الاكسل للتنبؤ بقيمة Y من أجل قيمة معينة للمتغير X بالاستناد إلى معادلة الانحدار الخطي لـ Y على X.
تذكير
تستخدم معادلة الانحدار الخطي البسيط في التنبؤ Forecasting قيمة المتغير التابع y من أجل قيمة معينة للمتغير المستقل x، والطريقة التقليدية هي تعويض قيمة x في معادلة الانحدار بعد ايجاد قيم الثوابت a وb.
يتضمن برنامج Microsoft Excel دالة إحصائية التي تقوم باالتنبؤ بقيم المتغير التابع Y بتأثيرات التغيير في قيمة المتغير المستقل X
الدالة FORECAST
تُستخدم الدالة FORECASY للتنبؤ بقيمة y من أجل قيمة معينة للمتغير x بالاستناد إلى معادلة الانحدار الخطي لـ y على x، والشكل العام لهذه الدالة هي:
= FORCAST(X;Known_y’s; Known_x’s)
حيث:
x: القيمة لـ x التي عندها نريد أن نتنبأ بقيمة المتغير التابع y.
Known_y’s: تمثل نطاق الخلايا المرجعية لقيم المتغير التابع y.
Known_x’s: تمثل نطاق الخلايا المرجعية لقيم المتغير المستقل x.
ملاحظات حول الدالة FORECAST
1-إذا كانت الوسيطة X قيمة غير رقمية فترجع الدالة قيمة الخطأ !VALUE#.
2-إذا كان عدد بيانات المتغيرين (عدد خلايا الوسطاء Known_y’s و Known_x’s) غير متساوي عندئذ ترجع الدالة قيمة الخطأ غير قابل للتطبيق N/A#
3- ترجع الدالة قيمة الخطأ !DIV/0 # إذا كان تباين المتغير المستقل (تباين الوسيطة Known_x’s) يساوي الصفر.
تطبيق عملي (1)
ليكن لدينا الجدول التالي الذي يمثل الدخل والإنفاق على المعيشة لمجموعة من الأسر بآلاف الليرات السورية شهرياً، حيث Y يمثل الإنفاق على المعيشة وX يمثل دخل الأسرة.
والتي قمنا بحساب ثوابتها في المقال السابق كما هو موضح في الشكل الآتي:
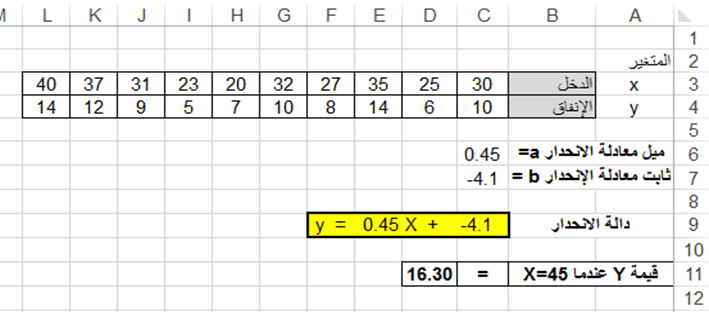
والمطلوب ايجاد القيمة التنبؤية لـ Y عندما X=45
التنفيذ:
ندخل في الخلية D11 الدالة:
=FORECAST(45;C4:L4; C3:L3)
وتظهر النتيجة: Y=16.30، كما هو مبين في الشكل الآتي:
في النهاية أعزائي القراء أتمنى أن تكون هذه التدوينة مفيدة وتساعدكم لمعرفة المزيد عن الاكسل، وإلى لقاءات قادمة ومتجددة على مدونتكم مدونة النائب للعلوم والتكنلوجيا. وأريد أن أطلب منكم ألا تترددوا أبداً في طرح أي سؤال علينا في التعليقات أو من خلال صفحتنا الرسمية على الفيس بوك حيث نتواجد هناك باستمرار. وإذا كان لديكم استفسارات أخرى يمكنكم دائماً مرسلتنا عبر هذا الرابط.
عزيزي القارئ عندما تكون المعلومات الاحصائية المتوفرة تتعلق بسلوك متغيرين أو أكثر مثل: دراسة العلاقة بين دخول الافراد ونفقاتهم، أو دراسة العلاقة بين معدل الوفيات ومعدل التحضر، أو دراسة العلاقة بين عدد السياح وايراداتهم….، نقوم بدراسة وجود أم عدم وجود علاقة بينهما، وتحديد قوتها ونوعها في حال وجودها، وهل هي طردية أم عكسية وماهي هذ العلاقة هل هي علاقة انحدار خطي أم غير خطي؟
في هذا المقال سنتناول دراسة العلاقة الخطية بين المتغيرات باستخدام الاكسل.
تذكير
الانحدار Regression: هو أسلوب يمكن بواسطته تقدير قيم أحد المتغيرين بمعلومية قيم المتغير الآخر عن طريق معادلة الانحدار وله أنواع:
الانحدار الخطي البسيط Simple Linear Regression: كلمة “بسيط” تعني ان المتغير التابع Y يعتمد على متغير مستقل واحد هو X، وكلمة “خطي” تعني ان العلاقة بين المتغيرين (X,Y) علاقة خطية.
الانحدار المتعدد MultipleRegression: يعني ان المتغير التابع Y يعتمد على أكثر من متغير مستقل.
الانحدار غير الخطي Nonlinear regression: يعني ان العلاقة بين المتغير التابع Y والمتغيرات المستقلة غير خطية، كأن تكون من الدرجة الثانية او أسية أو …
تذكير:
يسمى المستقيم الذي يصف العلاقة بين متغيرين أو ظاهرتين بمستقيم الانحدار Regression Line، ويعبر عنه بمعادلة من الدرجة الأولى من الشكل الآتي:
yi = axi +b
حيث:
y يمثل المتغير التابع.
x يمثل المتغير المستقل.
a ثابت يسمى معامل الانحدار وهو يعبر عن ميل المستقيم، ويدل على مقدار التغير في القيم المقدرة للمتغير Y لكل وحدة تغير واحدة في المتغير المستقل X.
b ثابت معادلة الانحدار ويمثل نقطة تقاطع خط الانحدار مع المحور العمودي في مستوي المحورين الإحداثيين، ويدل على قيمة Y عندما X تساوي الصفر.
وبالتالي لتحديد معادلة الانحدار يجب تقدير الثوابت a وb ، يمكن الرجوع الى مراجع الاحصاء للتعرف على طريقة حسابها.
بينما في هذا المقال سنتعرف على كيفية حسابها باستخدام دوال الاكسل
يتضمن برنامج Microsoft Excel مجموعة من الدوال الإحصائية التي تقوم بحساب ثوابت معادلة الانحدار الخطي البسيط والتي بموجبها نتحقق من معنوية معاملات النموذج ومن معنوية النموذج الرياضي ومدى ملاءمته لتمثيل بيانات الظواهر الاجتماعية والنفسية أو التربوية قيد الدراسة والبحث
الدالة INTERCEPT
تُستخدم الدالة INTERCEPTلحساب الثابت b في معادلة الانحدار، والشكل العام لهذه الدالة هي:
= INTERCEPT (Known_y’s; Known_x’s)
حيث:
Known_y’s: تمثل نطاق الخلايا المرجعية لقيم المتغير التابع y.
Known_x’s: تمثل نطاق الخلايا المرجعية لقيم المتغير المستقل x.
الدالة SLOPE
تُستخدم الدالة SLOPE لحساب الثابت a في معادلة الانحدار (ميل معادلة الانحدار)، والشكل العام لهذه الدالة هي:
= SLOPE(Known_y’s; Known_x’s)
حيث:
Known_y’s: تمثل نطاق الخلايا المرجعية لقيم المتغير التابع y.
Known_x’s: تمثل نطاق الخلايا المرجعية لقيم المتغير المستقل x.
ملاحظات حول الدالتين INTERCEPT وSLOPE:
1-يجب أن تكون بيانات الوسطاء أرقاماً أو مراجع خلايا تحتوي على أرقام.
2-إذا احتوت بعض خلايا نطاق الخلايا المطبق عليها الدالة على نص أو قيمة منطقية أو أنها فارغة فيتم تجاهلها.
3-إذا كان عدد بيانات المتغيرين (عدد خلايا الوسطاء Known_y’s و Known_x’s) غير متساوي عندئذ ترجع الدالة قيمة الخطأ غير قابل للتطبيق #N/A
تطبيق عملي (1)
ليكن لدينا الجدول التالي الذي يمثل الدخل والإنفاق على المعيشة لمجموعة من الأسر بآلاف الليرات السورية شهرياً، حيث Y يمثل الإنفاق على المعيشة وX يمثل دخل الأسرة، والمطلوب ايجاد معادلة مستقيم إنحدار Y على X.
الدخل
30
25
35
27
32
20
23
31
37
40
الإنفاق
10
6
14
8
10
7
5
9
12
14
التنفيذ:
يمكن تنظيم ورقة العمل كما في الشكل
لإيجاد معادلة مستقيم انحدار Y على X :
أولاً: ندخل في الخلية C6 دالة ميل معادلة الانحدار، أي:
=SLOPE (C4:L4; C3:L3)
ثانياً: ندخل في الخلية C7 دالة ثابت معادلة الانحدار، أي:
=INTERCEPT (C4:L4; C3:L3)
ثالثاً: ندخل في الخلية E9 الصيغة:
=C6
رابعاً: ندخل في الخلية C9 الصيغة:
=C7
والشكل الآتي يوضح شكل نتائج الحسابات
في النهاية أعزائي القراء أتمنى أن تكون هذه التدوينة مفيدة وتساعدكم لمعرفة المزيد عن الاكسل، وإلى لقاءات قادمة ومتجددة على مدونتكم مدونة النائب للعلوم والتكنلوجيا. وأريد أن أطلب منكم ألا تترددوا أبداً في طرح أي سؤال علينا في التعليقات أو من خلال صفحتنا الرسمية على الفيس بوك حيث نتواجد هناك باستمرار. وإذا كان لديكم استفسارات أخرى يمكنكم دائماً مرسلتنا عبر هذا الرابط.
عزيزي القارئ جدول التوزيع التكراري Frequency Table هو: وسيلة لتلخيص وتنظيم البيانات الإحصائية في عدد محدود من الفئات في صورة جداول أو رسوم بيانية، تسهل طريقة فهمها بمجرد النظر إليها سواء كانت بيانات نوعية أو كمية، من خلال ترتيبها تنازلياً أو تصاعدياً وحساب مرات تكرارها.
تنويه:
من المعروف أن البيانات الإحصائية تنقسم إلى نوعين هما:
بيانات نوعية (وصفية)، مثل: الوضع الاجتماعي، المستوى التعليمي، لون الشعر، الجنس، فصيلة الدم،….
بيانات كمية، مثل: عدد الأولاد، الطول، الوزن، العمر، علامات الطلاب، ….
ناقشنا في مقال سابق آلية حساب التكرارات لبيانات نوعية، وسنناقش في هذا المقال آلية حساب التكرارارية للبيانات الكمية.
يمكن عمل أربعة أنواع من التكرارات للبيانات الكمية هي: التكرار العادي والتكرار التجميعي الصاعد والتكرار التجميعي الهابط والتكرار النسبي.
حدد عدد ومدى كل فئة (يتم ذلك حسب طبيعة البيانات وخبرة المستخدم، أو بالاعتماد على طرق إحصائية).
أدخل الحد الأعلى والأدنى لكل فئة في نطاق من الخلايا المرجعية.
لحساب التكرار العادي لكل فئة في نطاق الخلايا المرجعية المجاورة للخلايا التي تحوي الفئات، استخدام الدالة FREQUENCY كما يلي:
حدد نطاق الخلايا المرجعية الفارغة المجاورة للخلايا التي تحوي الفئات.
أدخل الدالة الآتية: FREQUENCY (Data_array; Bins_array)= حيث: Data_array: نطاق الخلايا المرجعية التي تحوي البيانات الكمية. Bins_array: نطاق الخلايا المرجعية التي تحوي الحد الأعلى للفئات.
اضغط المفتاحين SHIFT+CTRL معاً مع الاستمرار والضغط على مفتاح الإدخال Enter. عندئذٍ سيمتلئ نطاق الخلايا المحدد في الخطوة الأولى بتكرارات كل فئة.
لحساب التكرار التجميعي الصاعد لكل فئة، كالآتي:
للفئة الأولى استخدم الصيغة: = [مرجع الخلية التي تحوي على التكرار العادي للفئة الأولى]
للفئة الثانية استخدم الصيغة: = [مرجع الخلية التي تحوي على التكرار التجميعي الصاعد للفئة الأولى] + [مرجع الخلية التي تحوي على التكرار العادي للفئة الثانية]
ثم عمم الصيغة للفئة الثانية على باقي الفئات.
لحسابالتكرار التجميعي الهابط لكل فئة، كالآتي:
للفئة الأولى استخدم الصيغة: = [مرجع الخلية التي تحوي على التكرار التجميعي الصاعد للفئة الأخيرة] أو = [مرجع الخلية التي تحوي على مجموع التكرارات العادية]
للفئة الثانية استخدم الصيغة: = [مرجع الخلية التي تحوي على التكرار التجميعي الهابط للفئة الأولى] – [مرجع الخلية التي تحوي على التكرار العادي للفئة الأولى]
ثم عمم الصيغة للفئة الثانية على باقي الفئات.
لحساب التكرار النسبي لكل فئة استخدام الصيغة:
= التكرار العادي للفئة / مجموع التكرارات العادية
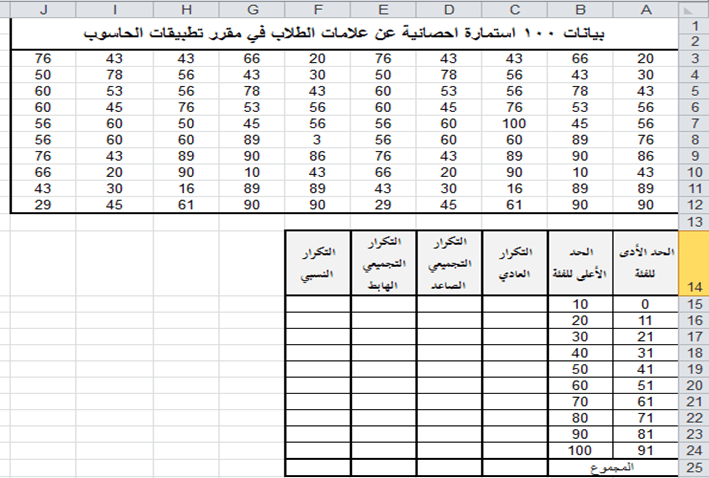
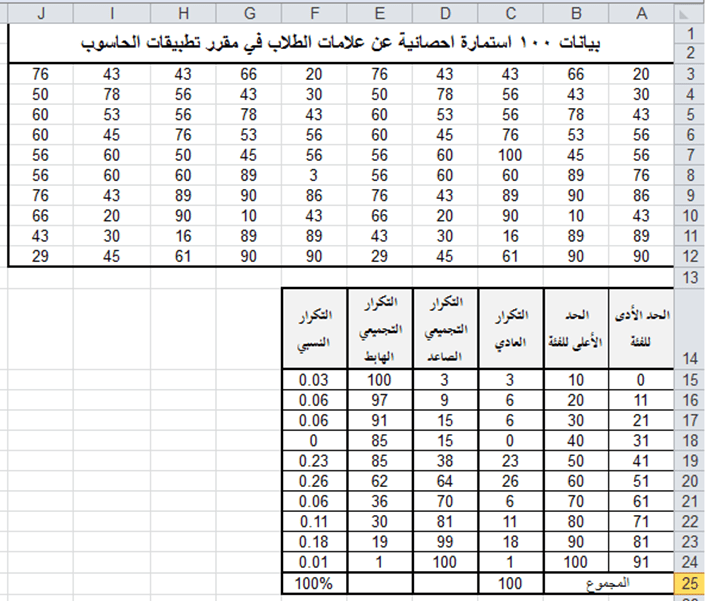
تطبيق عملي (1): احسب التكرارات العادية لبيانات 100 استمارة إحصائية تتضمن علامات الطلاب في مقرر تطبيقات الحاسوب وهي:
بيانات 100 استمارة احصائية عن علامات الطلاب في مقرر تطبيقات الحاسوب
20
66
43
43
76
20
66
43
43
76
30
43
56
78
50
30
43
56
78
50
43
78
56
53
60
43
78
56
53
60
56
53
76
45
60
56
53
76
45
60
56
45
100
60
56
56
45
50
60
56
76
89
60
60
56
3
89
60
60
56
86
90
89
43
76
86
90
89
43
76
43
10
90
20
66
43
10
90
20
66
89
89
16
30
43
89
89
16
30
43
90
90
61
45
29
90
90
61
45
29
التنفيذ:
أولاً: نقوم بادخال البيانات الى ورقة العمل في الاكسل كما في الشكل التالي:
أدخلنا البيانات أعلاه على صفحة الاكسل ضمن الخلايا المرجعية من A3 وحتى J12
وأدخلنا الفئات السابقة في نطاق من الخلايا المرجعية B24:A15
ثانياً: اجراءات حساب التوزيع التكرار العادي:
1- حدد نطاق الخلايا المرجعية الفارغة C24:C15.
2 – أدخل الدالة الآتية:
=FREQUENCY(A3:J12;B15:B24)
3- اضغط المفتاحين SHIFT+CTRL معاً مع الاستمرار والضغط على مفتاح الإدخال Enter، عندئذٍ سيمتلئ نطاق الخلايا C15:C24 بتكرارات كل فئة، كما في الشكل أددناه.
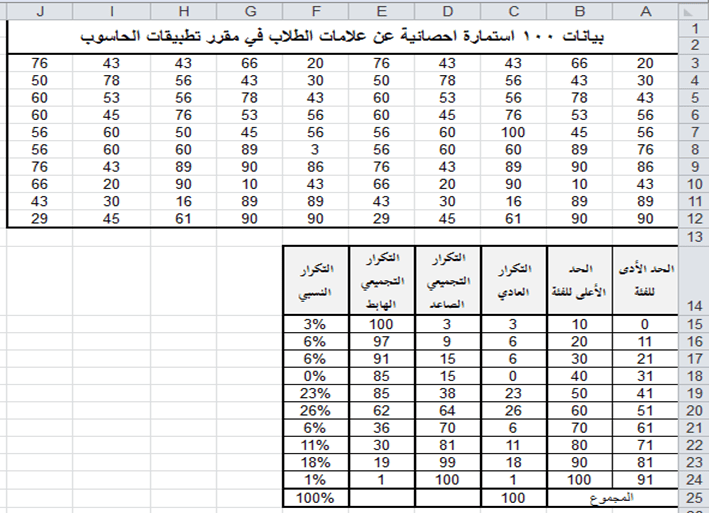
ثالثا: اجراءات حساب التكرارات الصاعدة:
1- في الخلية D15 اكتب الصيغة الآتية:
= C15
2- في الخلية D16 اكتب الصيغة الآتية:
= D15+C16
3- عمم الصيغة في الخلية D16 على الخلايا من D17 ولغاية D24،
سيمتلئ نطاق الخلايا D15:D24 بتكرارات كل فئة، كما في الشكل أددناه.
رابعاً: اجراءات حساب التكرارات الهابطة:
1- في الخلية E15 اكتب الصيغة الآتية:
= C25
2- في الخلية E16 اكتب الصيغة الآتية:
= E15+C15
3- عمم الصيغة في الخلية E16 على الخلايا من E17 ولغاية E24،
سيمتلئ نطاق الخلايا E15:E24 بتكرارات كل فئة، كما في الشكل أددناه.
خامساً: اجراءات حساب التكرارات النسبية:
1- في الخلية F15 اكتب الصيغة الآتية:
= C15/$C$25
2- عمم الصيغة في الخلية F15 على الخلايا من F16 ولغاية F24،
سيمتلئ نطاق الخلايا F15:F24 بتكرارات كل فئة، كما في الشكل أددناه.
تنويه: يمكن تحويل الأرقام في خلايا التكرار النسبي إلى تنسيق النسبة المئوية %، وذلك:
بتحديد خلايا النطاق B15:B25
ثم النقر على أيقونة النسبة المئوية الموجودة في مجموعة: الرقم Number” ضمن تبويب “الصفحة الرئيسية HOME”
عندئذ تأخذ بيانات النطاق كما في الشكل ادناه
في النهاية أعزائي القراء أتمنى أن تكون هذه التدوينة مفيدة وتساعدكم لمعرفة المزيد عن الاكسل، وإلى لقاءات قادمة ومتجددة على مدونتكم مدونة النائب للعلوم والتكنلوجيا. وأريد أن أطلب منكم ألا تترددوا أبداً في طرح أي سؤال علينا في التعليقات أو من خلال صفحتنا الرسمية على الفيس بوك حيث نتواجد هناك باستمرار. وإذا كان لديكم استفسارات أخرى يمكنكم دائماً مرسلتنا عبر هذا الرابط.
عزيزي القارئ جدول التوزيع التكراري Frequency Table هو: وسيلة لتلخيص وتنظيم البيانات الإحصائية في عدد محدود من الفئات في صورة جداول أو رسوم بيانية، تسهل طريقة فهمها بمجرد النظر إليها سواء كانت بيانات نوعية أو كمية، من خلال ترتيبها تنازلياً أو تصاعدياً وحساب مرات تكرارها.
تنويه:
من المعروف أن البيانات الإحصائية تنقسم إلى نوعين هما:
بيانات نوعية (وصفية)، مثل: الوضع الاجتماعي، المستوى التعليمي، لون الشعر، الجنس، فصيلة الدم،….
بيانات كمية، مثل: عدد الأولاد، الطول، الوزن، العمر، علامات الطلاب، ….
أدخل البيانات الوصفية في نطاق من الخلايا المرجعية.
احصر الصفات المختلفة في البيانات الوصفية المدخلة.
أدخل الصفات المختلفة في نطاق من الخلايا المرجعية (أفقياً أو عمودياً حسب الرغبة).
أوجد تكرار كل صفة في نطاق من الخلايا المرجعية المجاورة للخلايا التي تحوي الصفات المختلفة، باستخدام الدالة COUNTIF.
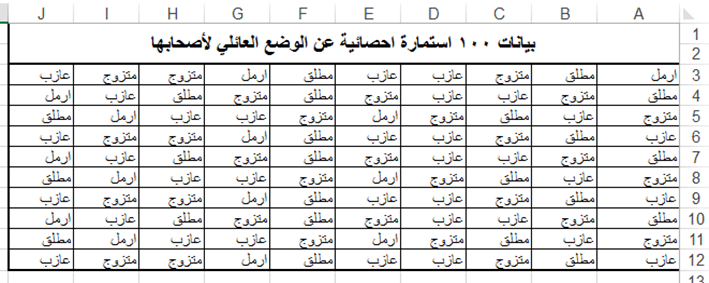
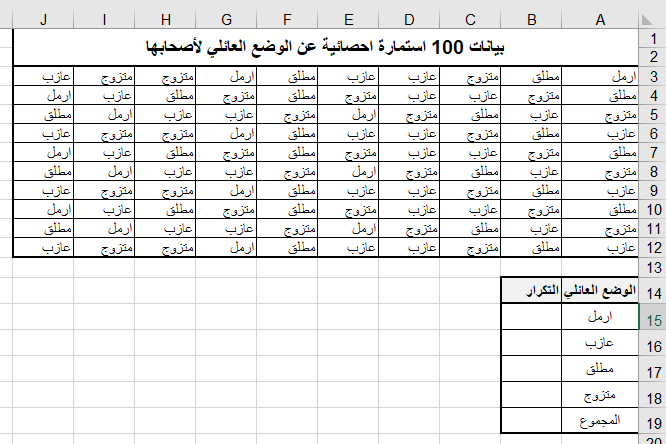
تطبيق عملي (1): ليكن لدينا مئة استمارة احصائية تتضمن بيانات عن الوضع العائلي لأصحابها وهذه البيانات هي:
ارمل
مطلق
متزوج
عازب
عازب
مطلق
ارمل
متزوج
متزوج
عازب
مطلق
متزوج
عازب
عازب
متزوج
مطلق
متزوج
مطلق
عازب
ارمل
متزوج
عازب
مطلق
متزوج
ارمل
متزوج
عازب
عازب
ارمل
مطلق
عازب
مطلق
متزوج
عازب
عازب
مطلق
ارمل
متزوج
متزوج
عازب
مطلق
متزوج
عازب
عازب
متزوج
مطلق
متزوج
مطلق
عازب
ارمل
متزوج
عازب
مطلق
متزوج
ارمل
متزوج
عازب
عازب
ارمل
مطلق
عازب
مطلق
متزوج
عازب
عازب
مطلق
ارمل
متزوج
متزوج
عازب
مطلق
متزوج
عازب
عازب
متزوج
مطلق
متزوج
مطلق
عازب
ارمل
متزوج
عازب
مطلق
متزوج
ارمل
متزوج
عازب
عازب
ارمل
مطلق
عازب
مطلق
متزوج
عازب
عازب
مطلق
ارمل
متزوج
متزوج
عازب
والمطلوب: حساب عدد تكرارات كل صفة من صفات الوضع العائلي (ارمل – عازب – مطلق – متزوج).
التنفيذ:
أولاً: نقوم بادخال البيانات الى ورقة العمل في الاكسل كما في الشكل التالي:
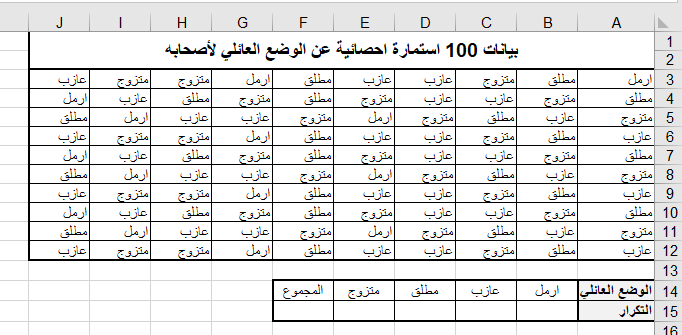
ثانياً: نصميم جدول التوزيعات التكراريةيمكن للمستخدم تصميمه افقياً أو عمودياً
الأسلوب الأول: تصميم جدول التوزيعات التكرارية للبيانات النوعيةأفقياً:
أدخل الصفات السابقة في نطاق من الخلايا المرجعية B14:E14 كما في الشكل التالي:
ثالثا: لحساب تكرارات كل صفة، أدخل الدالة الآتية في الخلية B15:
=COUNTIF($A$3:$J$12;B14)
ثم اسحب من مقبض التعبئة للخلية B15 لتعميم الدالة السابقة على الخلايا من C15 ولغاية الخلية E15.
رابعاً: احسب مجموع التكرارات في الخلية F15 باستخدام الدالة:
=SUM(B15:E15)
ويبين الشكل التالي المظهر النهائي لورقة العمل بعد تطبيق الخطوات أعلاه.
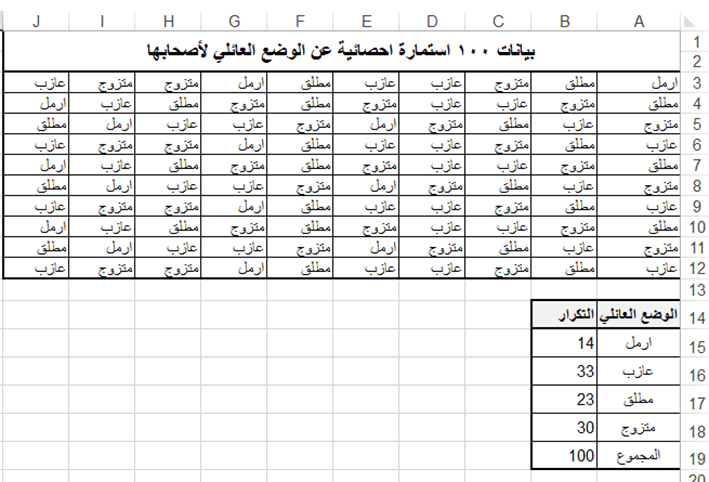
الأسلوب الثاني: تصميم جدول التوزيعات التكرارية للبيانات النوعيةعمودياً:
أدخل الصفات السابقة في نطاق من الخلايا المرجعية B18:E15 كما في الشكل التالي:
ثالثا: لحساب تكرارات كل صفة، أدخل الدالة الآتية في الخلية B15:
=COUNTIF($A$3:$J$12;A15)
ثم اسحب من مقبض التعبئة للخلية B15 لتعميم الدالة السابقة على الخلايا من B16 ولغاية الخلية B18.
رابعاً: احسب مجموع التكرارات في الخلية B19 باستخدام الدالة:
=SUM(B15:B18)
ويبين الشكل التالي المظهر النهائي لورقة العمل بعد تطبيق الخطوات أعلاه.
في النهاية أعزائي القراء أتمنى أن تكون هذه التدوينة مفيدة وتساعدكم لمعرفة المزيد عن الاكسل، وإلى لقاءات قادمة ومتجددة على مدونتكم مدونة النائب للعلوم والتكنلوجيا. وأريد أن أطلب منكم ألا تترددوا أبداً في طرح أي سؤال علينا في التعليقات أو من خلال صفحتنا الرسمية على الفيس بوك حيث نتواجد هناك باستمرار. وإذا كان لديكم استفسارات أخرى يمكنكم دائماً مرسلتنا عبر هذا الرابط.
عزيزي القارئ يتضمن برنامج Microsoft Excel مجموعة كبيرة جداً من الدوال الإحصائية التي تقوم بحساب كافة المقاييس والمؤشرات الإحصائية المتعلقة بظاهرة أو أكثر من الظواهر الاجتماعية أو النفسية أو التربوية أو المالية بمجرد كتابة الصيغة الرياضية الملاءمة للدالة وتحديد نطاق البيانات الخاصة بالظاهرة المدروسة.
إن مقاييس النزعة المركزية غير كافية لوحدها تحديد خواص الظاهرة المدروسة بشكل جيد، ولاسيما في مجال المقارنة بين عدة مجموعات من الظواهر المدروسة، لذلك ندرس مقاييس التشتت لوصف درجة ابتعاد أو تشتت أو تفاوت القيم حول وسطها الحسابي، ومن أهم مقاييس التشتت: الانحراف المعياري والتباين.
في الاحصاء: يعرف التباين Variance لمجموعة قيم بأنه مربع الانحراف المعياري، بعبارة أخرة هو مقياس للتشتت الإحصائي للقيم الممكنة حول وسطها الحسابي. ونميز بين نوعين من التباينات:
أولاً: التباين لعينة مأخوذة من مجتمع: وهو حاصل قسمة مجموع مربعات فروق القيمة عن وسطها الحسابي على عددها ناقص واحد، ويحسب في الإحصاء باستخدام العلاقة:
ثانياً: التبياين للمجتمع بأكمله: وهو حاصل قسمة مجموع مربعات فروق القيمة عن وسطها الحسابي على عددها، ويحسب في الإحصاء باستخدام العلاقة:
في الاكسل: يوجد أربعة دوال لحساب الانحراف المعياري:
الدالة الأولى VAR.S: تُستخدم الدالة VAR.S في حساب التباين لعينة مأخوذة من مجتمع (وتتجاهل القيم المنطقية والنص في العينة)، والشكل العام لهذه الدالة هو:
= VAR.S (Number1; Number2; …)
حيث:
Number1; Number1; …: وسطاء الدالة،وتمثل نطاق الخلايا المرجعية التي تحتوي على القيم العددية (أو القيم العددية أو مراجع خلايا تحتوي على قيم عددية) المراد حساب تباينها.
تنويه:
تفترض الدالة VAR.S أن وسيطاتها تمثل عينة من مجتمع. إذا كانت بياناتك تمثل المجتمع بأكمله، فاحسب حينئذٍ التباين باستخدام VAR.P.
يتم تجاهل الخلايا الفارغة أو القيم المنطقية أو النص أو قيم الخطأ في النطاق أو مراجع الخلايا.
تتسبب الوسيطات التي تكون عبارة عن قيم خطأ أو نص لا يمكن ترجمته إلى أرقام في حدوث أخطاء.
إذا أردت تضمين قيم منطقية وتمثيلات نصية للأرقام في مرجع كجزء من العمليات الحسابية، فاستخدم الدالة VARA.
الدالة الثانية VARA: تُستخدم الدالة VARA في حساب التباين لعينة مأخوذة من مجتمع، والشكل العام لهذه الدالة هو:
= VARA (Value1; Value2; …)
حيث:
Value1; Value1; …: وسطاء الدالة،وتمثل نطاق الخلايا المرجعية التي تحتوي على البيانات المراد حساب تباينها.
تنويه:
تفترض الدالة VARA أن وسيطاتها تمثل عينة من مجتمع. إذا كانت بياناتك تمثل المجتمع بأكمله، فاحسب حينئذٍ الانحراف المعياري باستخدام VARPA.
يمكن للوسيطات أن تكون عبارة عن أرقام أو أسماء أو نطاق خلايا أو مراجع تحتوي على أرقام؛ أو تمثيلات نصية لأرقام؛ أو قيم منطقية مثل TRUE وFALSE.
يتم تقييم الوسيطات التي تحتوي على TRUE كـ 1 (واحد)، بينما يتم تقييم الوسيطات التي تحتوي على نص أو FALSE كـ 0 (صفر).
تتسبب الوسيطات التي تكون عبارة عن قيم خطأ أو نص لا يمكن ترجمته إلى أرقام في حدوث أخطاء.
إذا كنت لا تريد تضمين قيم منطقية وتمثيلات نصية للأرقام في مرجع كجزء من العملية الحسابية، فاستخدم الدالة VAR.S.
الدالة الثالثة VAR.P: تُستخدم الدالة VAR.P في حساب التباين لمجتمع (وتتجاهل القيم المنطقية والنص في العينة)، والشكل العام لهذه الدالة هو:
= VARA .P (Number1; Number2; …)
حيث:
Number1; Number1; …: وسطاء الدالة،وتمثل نطاق الخلايا المرجعية التي تحتوي على القيم العددية (أو القيم العددية أو مراجع خلايا تحتوي على قيم عددية) المراد حساب تباينها.
تنويه:
تفترض الدالة VAR.P أن وسيطاتها تمثل المجتمع بأكمله. إذا كانت بياناتك تمثل عينة من مجتمع، فاحسب حينئذٍ الانحراف المعياري باستخدام VAR.S.
يتم تجاهل الخلايا الفارغة أو القيم المنطقية أو النص أو قيم الخطأ في النطاق أو مراجع الخلايا.
تتسبب الوسيطات التي تكون عبارة عن قيم خطأ أو نص لا يمكن ترجمته إلى أرقام في حدوث أخطاء.
إذا أردت تضمين قيم منطقية وتمثيلات نصية للأرقام في مرجع كجزء من العمليات الحسابية، فاستخدم الدالة VARPA.
الدالة الرابعة VARPA: تُستخدم الدالة VARPA في حساب الانحراف المعياري لمجتمع، والشكل العام لهذه الدالة هو:
= VARPA (Value1; Value2; …)
حيث:
Value1; Valuer1; …: وسطاء الدالة،وتمثل نطاق الخلايا المرجعية التي تحتوي البيانات المراد حساب تباينها.
تنويه:
تفترض الدالة VARPA أن وسيطاتها تمثل المجتمع بأكمله. وإذا كانت بياناتك تمثل عينة من المجتمع، فعليك حينئذٍ حساب الانحراف المعياري باستخدام VARA.
يمكن للوسيطات أن تكون عبارة عن أرقام أو أسماء أو نطاق خلايا أو مراجع تحتوي على أرقام؛ أو تمثيلات نصية لأرقام؛ أو قيم منطقية مثل TRUE وFALSE.
يتم تقييم الوسيطات التي تحتوي على TRUE كـ 1 (واحد)، بينما يتم تقييم الوسيطات التي تحتوي على نص أو FALSE كـ 0 (صفر).
تتسبب الوسيطات التي تكون عبارة عن قيم خطأ أو نص لا يمكن ترجمته إلى أرقام في حدوث أخطاء.
إذا كنت لا تريد تضمين قيم منطقية وتمثيلات نصية للأرقام في مرجع كجزء من العملية الحسابية، فاستخدم الدالة VAR.P.
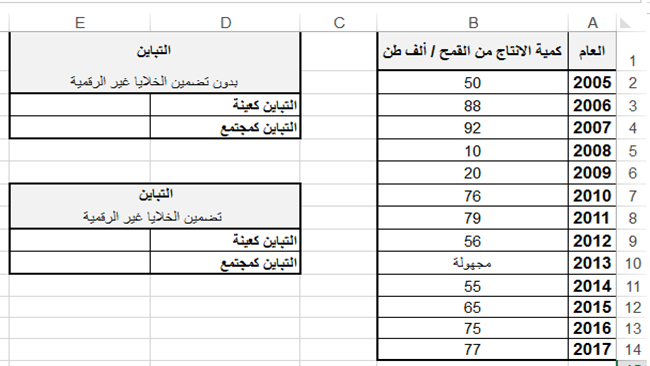
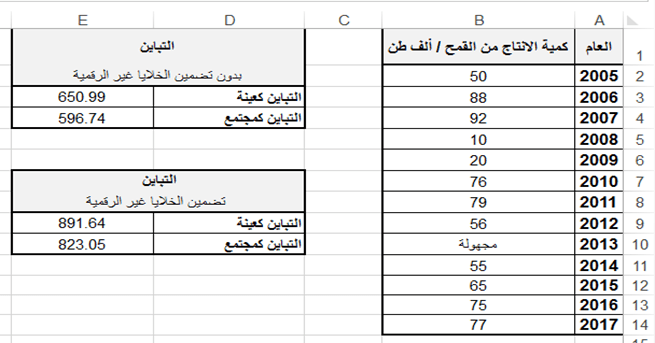
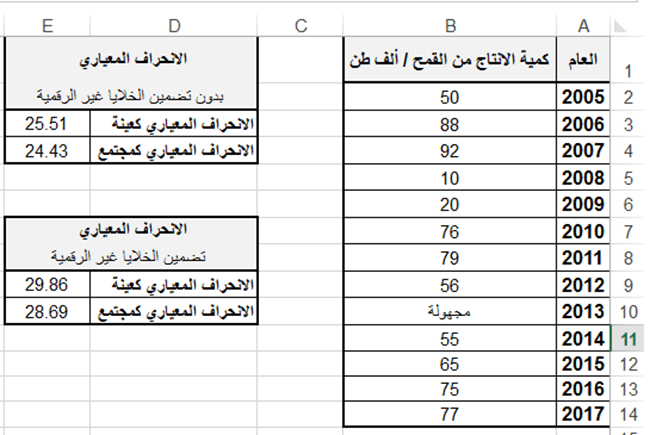
تطبيق عملي (1): ليكن الجدول التالي والذي يبين كميات الانتاج من القمح لعدة أعوام:
العام
كمية الإنتاج من القمح / ألف طن
2005
50
2006
88
2007
92
2008
10
2009
20
2010
76
2011
79
2012
56
2013
مجهولة
2014
55
2015
65
2016
75
2017
77
والمطلوب:
انقل البيانات إلى ورقة عمل في برنامج الاكسل.
اكتب الدالة المناسبة لحساب كل من التباين لكميات الإنتاج من القمح في الحالتين: الأولى بدون تضمين الخلايا التي تحوي على نص والثانية تضمين الخلايا التي تحوي على نص، على اعتبار البيانات كعينة من مجتمع.
اكتب الدالة المناسبة لحساب كل من التباين لكميات الإنتاج من القمح في الحالتين: الأولى بدون تضمين الخلايا التي تحوي على نص والثانية تضمين الخلايا التي تحوي على نص، على اعتبار البيانات كمجتمع بأكمله.
التنفيذ:
أولاً: نقوم بادخال البيانات الى ورقة العمل في الاكسل كما في الشكل التالي:
ثانياً: لحساب التباين في الخلية E3 بدون تضمين الخلايا التي تحوي على نص، على اعتبار البيانات كعينة نكتب:
E3 = VAR.S (B2:B14)
ثالثا: لحساب التباين في الخلية E4 بدون تضمين الخلايا التي تحوي على نص، على اعتبار البيانات كمجتمع نكتب
E4 = VAR.P (B2:B14)
رابعاً: لحساب التباين في الخلية E9 مع تضمين الخلايا التي تحوي على نص، على اعتبار البيانات كعينة نكتب
E9 = VARA (B2:B14)
خامساً: لحساب التباين في الخلية E10 مع تضمين الخلايا التي تحوي على نص، على اعتبار البيانات كمجتمع نكتب:
E10 = VARPA (B2:B14)
ويبين الشكل التالي المظهر النهائي لورقة العمل بعد تطبيق الدوال أعلاه.
في النهاية أعزائي القراء أتمنى أن تكون هذه التدوينة مفيدة وتساعدكم لمعرفة المزيد عن الاكسل، وإلى لقاءات قادمة ومتجددة على مدونتكم مدونة النائب للعلوم والتكنلوجيا. وأريد أن أطلب منكم ألا تترددوا أبداً في طرح أي سؤال علينا في التعليقات أو من خلال صفحتنا الرسمية على الفيس بوك حيث نتواجد هناك باستمرار. وإذا كان لديكم استفسارات أخرى يمكنكم دائماً مرسلتنا عبر هذا الرابط.
عزيزي القارئ يتضمن برنامج Microsoft Excel مجموعة كبيرة جداً من الدوال الإحصائية التي تقوم بحساب كافة المقاييس والمؤشرات الإحصائية المتعلقة بظاهرة أو أكثر من الظواهر الاجتماعية أو النفسية أو التربوية أو المالية بمجرد كتابة الصيغة الرياضية الملاءمة للدالة وتحديد نطاق البيانات الخاصة بالظاهرة المدروسة.
إن مقاييس النزعة المركزية غير كافية لوحدها تحديد خواص الظاهرة المدروسة بشكل جيد، ولاسيما في مجال المقارنة بين عدة مجموعات من الظواهر المدروسة، لذلك ندرس مقاييس التشتت لوصف درجة ابتعاد أو تشتت أو تفاوت القيم حول وسطها الحسابي، ومن أهم مقاييس التشتت: الانحراف المعياري والتباين.
في الاحصاء: الانحراف المعياري Standard Deviation هو مقياس مدى بُعد القيم عن وسطها الحسابي. ونميز بين نوعين من الانحرافات المعيارية:
أولاً: الانحراف المعياري لعينة مأخوذة من مجتمع: وهو الجذر التربيعي الموجب لحاصل قسمة مجموع مربعات فروق القيمة عن وسطها الحسابي على عددها ناقص واحد، ويحسب في الإحصاء باستخدام العلاقة:
ثانياً: الانحراف المعياري للمجتمع بأكمله: وهو الجذر التربيعي الموجب لحاصل قسمة مجموع مربعات فروق القيمة عن وسطها الحسابي على عددها، ويحسب في الإحصاء باستخدام العلاقة:
في الاكسل: يوجد أربعة دوال لحساب الانحراف المعياري:
الدالة الأولى STDEV.S: تُستخدم الدالة STDEV.S في حساب الانحراف المعياري لعينة مأخوذة من مجتمع (وتتجاهل القيم المنطقية والنص في العينة)، والشكل العام لهذه الدالة هو:
= STDEV.S (Number1; Number2; …)
حيث:
Number1; Number1; …: وسطاء الدالة،وتمثل نطاق الخلايا المرجعية التي تحتوي على القيم العددية (أو القيم العددية أو مراجع خلايا تحتوي على قيم عددية) المراد حساب انحرافها المعياري.
تنويه:
تفترض الدالة STDEV.S أن وسيطاتها تمثل عينة من مجتمع. إذا كانت بياناتك تمثل المجتمع بأكمله، فاحسب حينئذٍ الانحراف المعياري باستخدام STDEV.P.
يجب أن تكون الوسيطات إما أرقام أو أسماء أو نطاق خلايا أو مراجع تحتوي على أرقام.
يتم تجاهل الخلايا الفارغة أو القيم المنطقية أو النص أو قيم الخطأ في النطاق أو مراجع الخلايا.
تتسبب الوسيطات التي تكون عبارة عن قيم خطأ أو نص لا يمكن ترجمته إلى أرقام في حدوث أخطاء.
إذا أردت تضمين قيم منطقية وتمثيلات نصية للأرقام في مرجع كجزء من العمليات الحسابية، فاستخدم الدالة STDEVA.
الدالة الثانية STDEVA: تُستخدم الدالة STDEVA في حساب الانحراف المعياري لعينة مأخوذة من مجتمع، والشكل العام لهذه الدالة هو:
= STDEVA (Value1; Value2; …)
حيث:
Value1; Value1; …: وسطاء الدالة،وتمثل نطاق الخلايا المرجعية التي تحتوي على البيانات المراد حساب انحرافها المعياري.
تنويه:
تفترض الدالة STDEVA أن وسيطاتها تمثل عينة من مجتمع. إذا كانت بياناتك تمثل المجتمع بأكمله، فاحسب حينئذٍ الانحراف المعياري باستخدام STDEVPA.
يمكن للوسيطات أن تكون عبارة عن أرقام أو أسماء أو نطاق خلايا أو مراجع تحتوي على أرقام؛ أو تمثيلات نصية لأرقام؛ أو قيم منطقية مثل TRUE وFALSE.
يتم تقييم الوسيطات التي تحتوي على TRUE كـ 1 (واحد)، بينما يتم تقييم الوسيطات التي تحتوي على نص أو FALSE كـ 0 (صفر).
تتسبب الوسيطات التي تكون عبارة عن قيم خطأ أو نص لا يمكن ترجمته إلى أرقام في حدوث أخطاء.
إذا كنت لا تريد تضمين قيم منطقية وتمثيلات نصية للأرقام في مرجع كجزء من العملية الحسابية، فاستخدم الدالة STDEV.S.
الدالة الثالثة STDEV.P: تُستخدم الدالة STDEV.P في حساب الانحراف المعياري لمجتمع (وتتجاهل القيم المنطقية والنص في العينة)، والشكل العام لهذه الدالة هو:
= STDEV.P (Number1; Number2; …)
حيث:
Number1; Number1; …: وسطاء الدالة،وتمثل نطاق الخلايا المرجعية التي تحتوي على القيم العددية (أو القيم العددية أو مراجع خلايا تحتوي على قيم عددية) المراد حساب انحرافها المعياري.
تنويه:
تفترض الدالة STDEV.P أن وسيطاتها تمثل المجتمع بأكمله. إذا كانت بياناتك تمثل عينة من مجتمع، فاحسب حينئذٍ الانحراف المعياري باستخدام STDEV.S.
يجب أن تكون الوسيطات إما أرقام أو أسماء أو نطاق خلايا أو مراجع تحتوي على أرقام.
بالنسبة للعينات كبيرة الحجم، تُرجع STDEV.S وSTDEV.P قيماً متساوية تقريباً.
يتم تجاهل الخلايا الفارغة أو القيم المنطقية أو النص أو قيم الخطأ في النطاق أو مراجع الخلايا.
تتسبب الوسيطات التي تكون عبارة عن قيم خطأ أو نص لا يمكن ترجمته إلى أرقام في حدوث أخطاء.
إذا أردت تضمين قيم منطقية وتمثيلات نصية للأرقام في مرجع كجزء من العمليات الحسابية، فاستخدم الدالة STDEVPA.
الدالة الرابعة STDEVPA: تُستخدم الدالة STDEVPA في حساب الانحراف المعياري لمجتمع، والشكل العام لهذه الدالة هو:
= STDEVPA (Value1; Value2; …)
حيث:
Value1; Valuer1; …: وسطاء الدالة،وتمثل نطاق الخلايا المرجعية التي تحتوي البيانات المراد حساب انحرافها المعياري.
تنويه:
تفترض الدالة STDEVPA أن وسيطاتها تمثل المجتمع بأكمله. وإذا كانت بياناتك تمثل عينة من المجتمع، فعليك حينئذٍ حساب الانحراف المعياري باستخدام STDEVA.
بالنسبة إلى عينات كبيرة الحجم، تُرجع STDEV.S وSTDEV.P قيماً متساوية تقريباً.
يمكن للوسيطات أن تكون عبارة عن أرقام أو أسماء أو نطاق خلايا أو مراجع تحتوي على أرقام؛ أو تمثيلات نصية لأرقام؛ أو قيم منطقية مثل TRUE وFALSE.
يتم تقييم الوسيطات التي تحتوي على TRUE كـ 1 (واحد)، بينما يتم تقييم الوسيطات التي تحتوي على نص أو FALSE كـ 0 (صفر).
تتسبب الوسيطات التي تكون عبارة عن قيم خطأ أو نص لا يمكن ترجمته إلى أرقام في حدوث أخطاء.
إذا كنت لا تريد تضمين قيم منطقية وتمثيلات نصية للأرقام في مرجع كجزء من العملية الحسابية، فاستخدم الدالة STDEV.P.
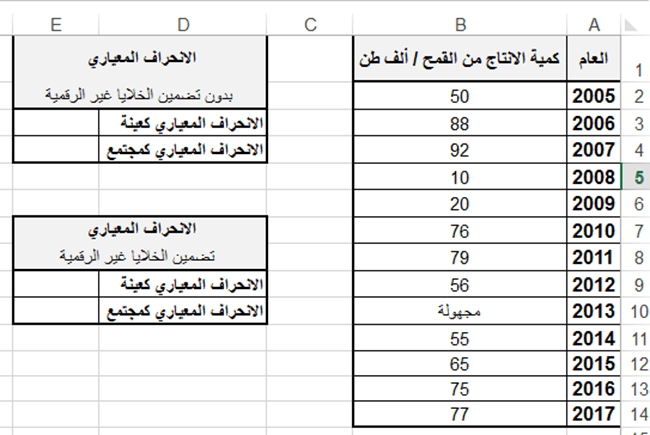
تطبيق عملي (1): ليكن الجدول التالي والذي يبين كميات الانتاج من القمح لعدة أعوام:
العام
كمية الإنتاج من القمح / ألف طن
2005
50
2006
88
2007
92
2008
10
2009
20
2010
76
2011
79
2012
56
2013
مجهولة
2014
55
2015
65
2016
75
2017
77
والمطلوب:
انقل البيانات إلى ورقة عمل في برنامج الاكسل.
اكتب الدالة المناسبة لحساب كل من الانحراف المعياري لكميات الإنتاج من القمح في الحالتين: الأولى بدون تضمين الخلايا التي تحوي على نص والثانية تضمين الخلايا التي تحوي على نص، على اعتبار البيانات كعينة من مجتمع.
اكتب الدالة المناسبة لحساب كل من الانحراف المعياري لكميات الإنتاج من القمح في الحالتين: الأولى بدون تضمين الخلايا التي تحوي على نص والثانية تضمين الخلايا التي تحوي على نص، على اعتبار البيانات كمجتمع بأكمله.
التنفيذ:
أولاً: نقوم بادخال البيانات الى ورقة العمل في الاكسل كما في الشكل التالي:
ثانياً: لحساب الانحراف المعياري في الخلية E3 بدون تضمين الخلايا التي تحوي على نص، على اعتبار البيانات كعينة نكتب
E3 = STDEV.S (B2:B14)
ثالثا: لحساب الانحراف المعياري في الخلية E4 بدون تضمين الخلايا التي تحوي على نص، على اعتبار البيانات كمجتمع نكتب
E4 = STDEV.P (B2:B14)
رابعاً: لحساب الانحراف المعياري في الخلية E9 مع تضمين الخلايا التي تحوي على نص، على اعتبار البيانات كعينة نكتب
E9 = STDEVA (B2:B14)
خامساً: لحساب الانحراف المعياري في الخلية E10 مع تضمين الخلايا التي تحوي على نص، على اعتبار البيانات كمجتمع نكتب:
E10 = STDEVPA (B2:B14)
ويبين الشكل التالي المظهر النهائي لورقة العمل بعد تطبيق الدوال أعلاه.
في النهاية أعزائي القراء أتمنى أن تكون هذه التدوينة مفيدة وتساعدكم لمعرفة المزيد عن الاكسل، وإلى لقاءات قادمة ومتجددة على مدونتكم مدونة النائب للعلوم والتكنلوجيا. وأريد أن أطلب منكم ألا تترددوا أبداً في طرح أي سؤال علينا في التعليقات أو من خلال صفحتنا الرسمية على الفيس بوك حيث نتواجد هناك باستمرار. وإذا كان لديكم استفسارات أخرى يمكنكم دائماً مرسلتنا عبر هذا الرابط.
عزيزي القارئ الربيع هو أحد مقاييس النزعة المركزية التكرارية في الاحصاء، حيث أن لمقاييس النزعة المركزية أهمية كبرى في التحليل الاحصائي للبيانات، لقدرتها على إعطائنا فكرة عامة وسهلة وواضحة عن قيم الظاهرة المدروسة.
في الإحصاء: الربيع الأول يمثل القيمة التي ترتيبها (أي يقع في منتصف المسافة الواقعة مابين بداية السلسلة الإحصائية والوسيط)، والربيع الثالث الذي يمثل القيمة التي ترتيبها (أي يقع في منتصف المسافة الواقعة ما بين الوسيط ونهاية السلسلة الإحصائية)، أما الربيع الثاني فيمثل الوسيط نفسه.
في الاكسل تُستخدم الدالة QUARTILE.INC لإيجاد الربيعات (الربيع الأول والربيع الثاني والربيع الثالث) من بين مجموعة من القيم، والشكل العام لهذه الدالة هو:
= QUARTILE.INC (Array; Quart)
حيث:
Array: تمثل نطاق الخلايا المرجعية التي تحتوي على قيم عددية (أو القيم العددية أو مراجع خلايا تحتوي على قيم عددية) المراد حساب الربيع لها.
Quart: تمثل قيمة الربيع المراد حسابه من بين مجموعة القيم، حيث إذا كانت:
Quart=0، تقوم الدالة QUARTILE.INC بإرجاع القيمة الصغرى
Quart=1، تقوم الدالة QUARTILE.INC بإرجاع الربيع الأول.
Quart=2، تقوم الدالة QUARTILE.INC بإرجاع الوسيط.
Quart=3، تقوم الدالة QUARTILE.INC بإرجاع الربيع الثالث.
Quart=4، تقوم الدالة QUARTILE.INC بإرجاع القيمة العظمى.
ملاحظات:
1-إذا كانت قيمة الوسيطة Quart عدداً غير صحيحاً، عندئذ تقوم الدالة QUARTILE.INC باختصاره (أي اعتماد القسم الصحيح فقط) مثلاً لو كان Quart 3.2 ستتعامل الدالة مع القيمة 3، وإذا كان Quart 3.7 ستتعامل الدالة مع القيمة (3
2-إذا كانت قيمة الوسيطة Quart أصغر من 0 أو أكبر من 4، عندئذ تقوم الدالة QUARTILE.INC بإرجاع قيمة الخطأ NUM!#.
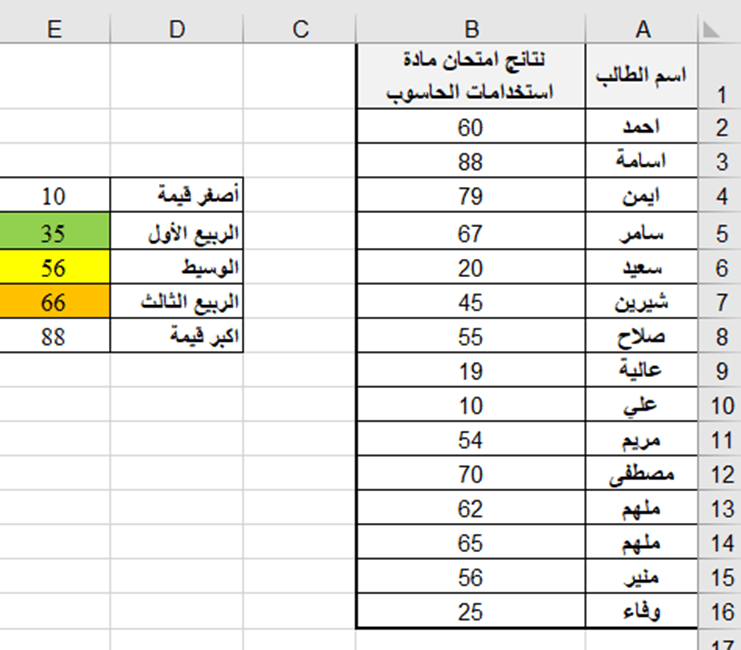
تطبيق عملي (1): لتحديد (أصغر قيمة، الربيع الأول، الوسيط، الربيع الثالث، أكبر قيمة) لنتائج الطلاب في امتحان استخدامات الحاسوب باستخدام الدالة QUARTILE.INC حسب ورق العمل الآتية:
التنفيذ:
لحساب أصغر قيمة باستخدام دالة الربيع QUARTILE.INC، ندخل في الخلية E4 الدالة الآتية:
= QUARTILE.INC (B2:B16;0)
لحساب الربيع الأول باستخدام دالة الربيع QUARTILE.INC، ندخل في الخلية E5 الدالة الآتية:
= QUARTILE.INC (B2:B16;1)
لحساب الوسيط باستخدام دالة الربيع QUARTILE.INC، ندخل في الخلية E6 الدالة الآتية:
= QUARTILE.INC (B2:B16;2)
لحساب الربيع الثالث باستخدام دالة الربيع QUARTILE.INC، ندخل في الخلية E7 الدالة الآتية:
= QUARTILE.INC (B2:B16;3)
لحساب أكبر قيمة باستخدام دالة الربيع QUARTILE.INC، ندخل في الخلية E8 الدالة الآتية:
= QUARTILE.INC (B2:B16;4)
في النهاية أعزائي القراء أتمنى أن تكون هذه التدوينة مفيدة وتساعدكم لمعرفة المزيد عن الاكسل، وإلى لقاءات قادمة ومتجددة على مدونتكم مدونة النائب للعلوم والتكنلوجيا. وأريد أن أطلب منكم ألا تترددوا أبداً في طرح أي سؤال علينا في التعليقات أو من خلال صفحتنا الرسمية على الفيس بوك حيث نتواجد هناك باستمرار. وإذا كان لديكم استفسارات أخرى يمكنكم دائماً مرسلتنا عبر هذا الرابط.
عزيزي القارئ المنوال هو أحد مقاييس النزعة المركزية التكرارية في الاحصاء، حيث أن لمقاييس النزعة المركزية أهمية كبرى في التحليل الاحصائي للبيانات، لقدرتها على إعطائنا فكرة عامة وسهلة وواضحة عن قيم الظاهرة المدروسة.
في الإحصاء: المنوال Mode بأنه القيمة الأكثر تكراراً من بين مجموعة من القيم.
في الاكسل تُستخدم الدالة MODE.SNGL لإيجاد المنوال لمجموعة من القيم، والشكل العام لهذه الدالة هو:
= MODE.SNGL (Number1; Number2; …)
حيث:
Number1; Number1; …: وسطاء الدالة،وتمثلنطاق الخلايا المرجعية التي تحتوي على قيم عددية (أو القيم العددية أو مراجع خلايا تحتوي على قيم عددية) المراد تحديد منوالها.
ملاحظات:
1-يجب أن تكون بيانات الوسطاء أرقاماً أو مراجع خلايا تحتوي على أرقام.
2-إذا احتوت بعض خلايا نطاق الخلايا المطلوب تحديد منوالها على نص أو قيمة منطقية أو أنها فارغة فيتم تجاهلها.
3-في حال عدم وجود قيمة متكررة، تقوم الدالة MODE.SNGL بإرجاع قيمة الخطأ N/A#.
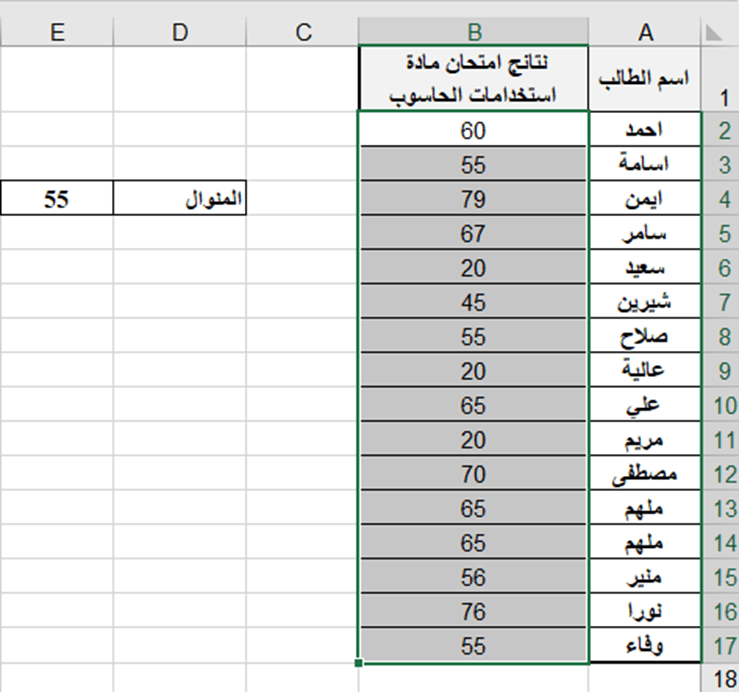
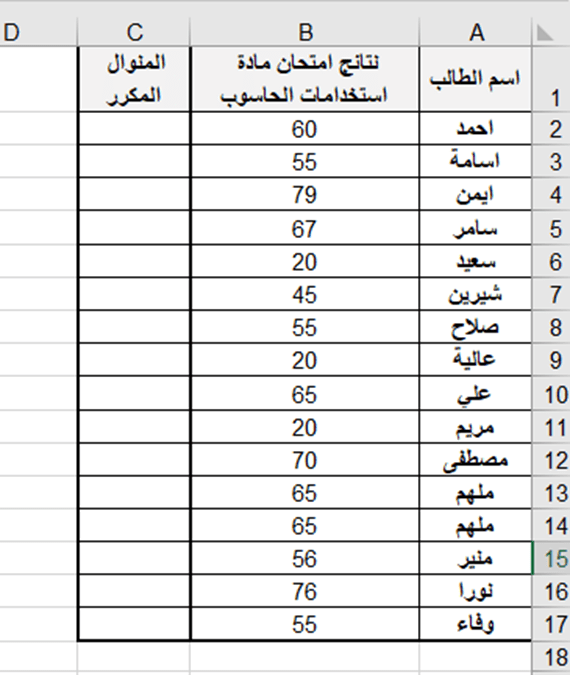
تطبيق عملي (1): لتحديد المنوال لنتائج الطلاب في امتحان استخدامات الحاسوب حسب ورق العمل الآتية:
لحساب المنوال ندخل في الخلية E4 الدالة الآتية:
= MODE.SNGL (B2:B17)
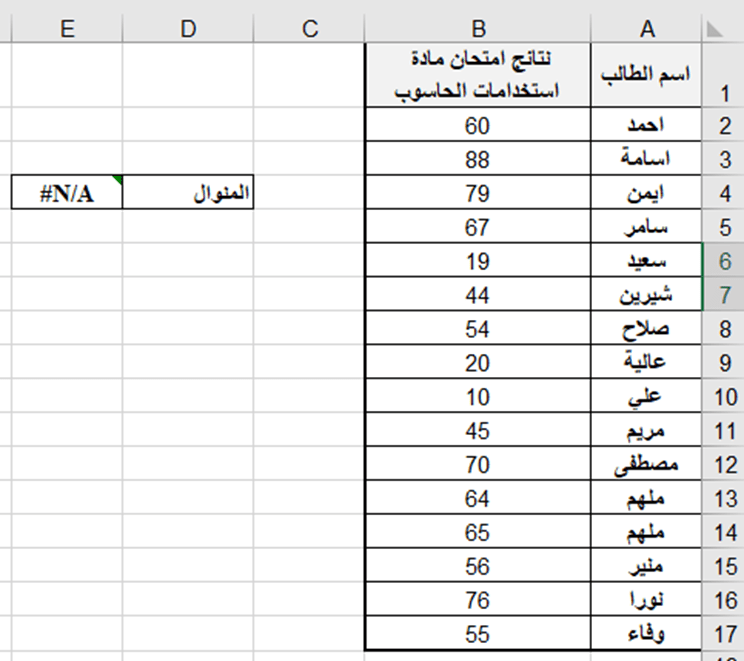
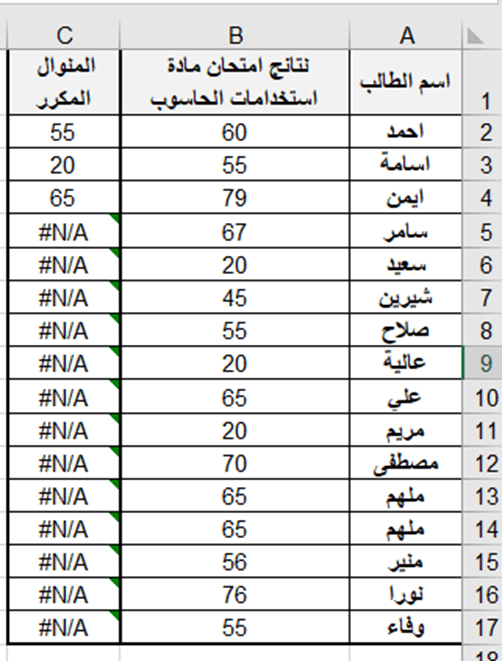
تطبيق عملي (2): لتحديد المنوال لنتائج الطلاب في امتحان استخدامات الحاسوب حسب ورق العمل الآتية:
لحساب المنوال ندخل في الخلية E4 الدالة الآتية:
= MODE.SNGL (B2:B17)
نلاحظ ان القيمة المنوال #N/A والسبب عدم وجود قيم مكررة.
تنويه هام:
إذا كان ضمن مجموعة القيم أكثر من قيمة لها نفس التكرار، عندئذ يمكن استخدام الدالة MODE.MULT للكشف عن تلك القيم. والشكل العام للدالة هو:
= MODE.MULT (Number1; Number2; …)
الدالة MODE.MULT تقوم بإرجاع مصفوفة عمودية بالقيم الأكثر تكراراً، ولتنفيذ ذلك نقوم بتنفيذ الخطوات التالية:
حدد نطاق خلايا فارغ كمصفوفة عمود بنفس عدد خلايا نطاق البيانات المطلوب تحديد منوالها، وحسب الشكل التالي حدد النطاق C2:C17.
أدخل الدالة:= MODE.MULT (B2:B17)
اضغط المفتاحين SHIFT+CTRL معاً مع الاستمرار والضغط على مفتاح الإدخال Enter. فتظهر النتائج كما في الجدول الآتي:
من الجدول السابق نلاحظ ظهور ثلاثة قيم مكررة لها نفس التكرار ومرتبة من الأكبر إلى الأصغر، أما بقية الخلايا فتظهر قيمة الخطأ #N/A.
في النهاية أعزائي القراء أتمنى أن تكون هذه التدوينة مفيدة وتساعدكم لمعرفة المزيد عن الاكسل، وإلى لقاءات قادمة ومتجددة على مدونتكم مدونة النائب للعلوم والتكنلوجيا. وأريد أن أطلب منكم ألا تترددوا أبداً في طرح أي سؤال علينا في التعليقات أو من خلال صفحتنا الرسمية على الفيس بوك حيث نتواجد هناك باستمرار. وإذا كان لديكم استفسارات أخرى يمكنكم دائماً مرسلتنا عبر هذا الرابط.